Person’s Recognition: A Criminal Can Be Found By Linguistic Analysis
The story had begun in 2011, when a hacker under the nickname "Hell" hacked into the email of the Russian opposition leader Alexei Navalny and made his correspondence public.
Hell had a personal blog and used warped language to make de-anonymizing harder. Although machine NLP (natural language processing) was not widely known at the time, it made sense to protect ourselves from future technologies that could provide a clue to the police.
Today, ten years later, the rationality of this approach seems to have been justified.
Linguistic And Semantic Files
Each person possesses a number of distinguishing features, from fingerprints to the way they walk. After some observations my machine learning colleagues and I have concluded that textual content, its stylistics, lexemes, and many other parameters are no exception. Today, the abundance of text materials, messages, posts and comments, allows us to highlight the unique features of a person using neural networks algorithms.
Nowadays criminals are forced to avoid areas with facial recognition cameras in order to hide from law enforcement agencies. The most cautious have even to stop using messengers in order to stay in the shadows.
In a sense, the situation for criminals is getting worse: law enforcement agencies do not have any video surveillance data from, let’s say, the 2000s. But the text content of hacker forums a decade ago is stored on the net. Making use of warped language is not a fundamental obstacle, since the model operates at the level of the words’ meaning regardless of spelling.
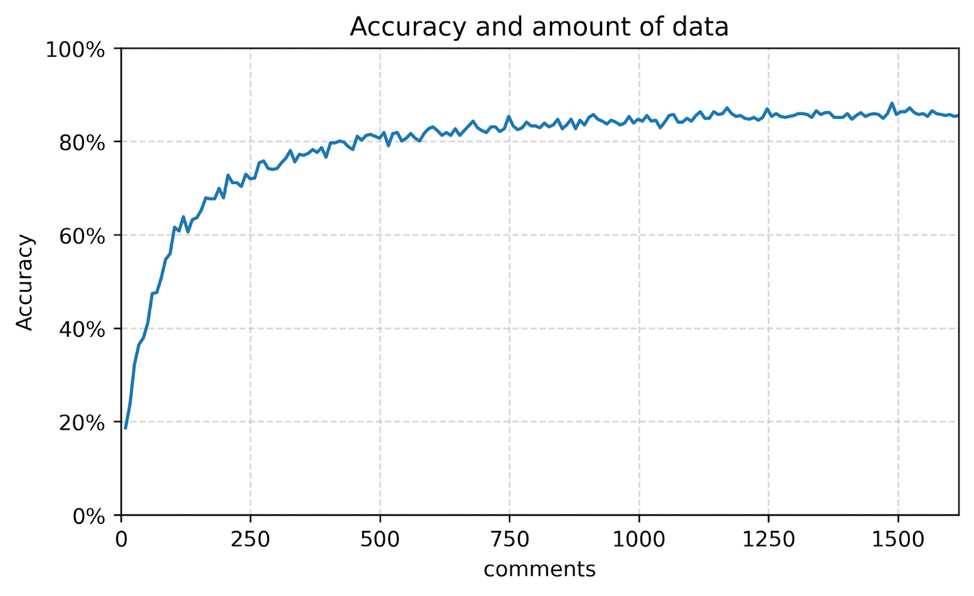
Recognizing Reddit.com Users With 87% Accuracy
In order to illustrate the process we have carried out an experiment. 500 users engaged in political disputes were selected, meaning all users were essentially talking about the same thing. The samples simulated a situation when a user logs out of the site, but after a while comes back and starts writing under a different nickname. That is, the user's early messages were placed in the training set, and the later ones in the test set.
The recognition accuracy has surpassed our initial expectations resulting in 87%, more than enough for a proof-of-concept. Moreover, this figure, if desired, can be increased extensively through the amount of data and additional model training, or intensively using more advanced techniques.
In order to reach 80% accuracy, 600 sentences per person were sufficient. This figure is a drop in the ocean compared to the amount of text materials generated by a single user in social networks and messengers.
A person’s identification becomes much easier as there is no need to search for a particular user among millions of social network followers; the search can be narrowed to the desired topic or a certain part of the social graphs using various technologies.
Troll Factories, Fake News, And Total Loss Of Anonymity
The technologies discussed can be applied to a variety of NLP tasks, at different scales. Linguistic and semantic files can be compiled collectively for the participants of the troll factory. The discussed models are also suitable for fake news recognition, since facts have semantic characteristics by definition. The meanings of the phrases ‘vaccines kill’ and ‘vaccines save’ are much easier to distinguish than the meanings of comments made by 500 people about politics.
Same as any other technology, it can be used both for good and evil. A great deal of text content is personalized and publicly available. Even more is available to owners of social networks and messengers. In a nutshell, using NLP algorithms anonymous stakeholder blogs can stop being anonymous.
The Technical Side. Speech2Vec And Cascade Models
While dealing with the tasks of machine processing for natural language, a word or sentence is transformed into a set of figures - a vector, where each number encodes semantic and linguistic components.
The most common patterns used are word-to-vector [word2vec] or sentence-to-vector [sentence2vec].
However, at this level, it is still impossible to distinguish the unique traits of a person. To achieve significant accuracy, it was necessary to increase the scale of formalization and implement vector representation for very long sequences. In fact, it turned out to be ‘speech to vector’, so let's call it speech2vec.
At the final stage of the classification task, a cascade of small models was used. In this case, it is more efficient and more accurate than a big one.
The advantages of this approach have recently been confirmed by Google researchers.
As a proof, our team has prepared a simplified version of the dataset, code and models so that anyone could make sure of the reality of the concept and understand the way it works. [there will be a link to the collab].
The idea that the absence of a face on an avatar guarantees anonymity proves to be wrong. Weak AI eliminates the word ‘anonymous’ from this canon.
Acrux Cyber Services, Data Science Team.

